Motivation
The c2rust project exists to help bridge the fact that there is a lot of valuable software written in C and that there have been great strides in making safer and more-reliable programming languages since C was designed.
Rust offers many modern improvements for C while still preserving the low-level control that makes it attractive. Beyond that, Rust provides new abstraction capabilities like parametricity, type-traits, methods, a module system, thread-safety, and more.
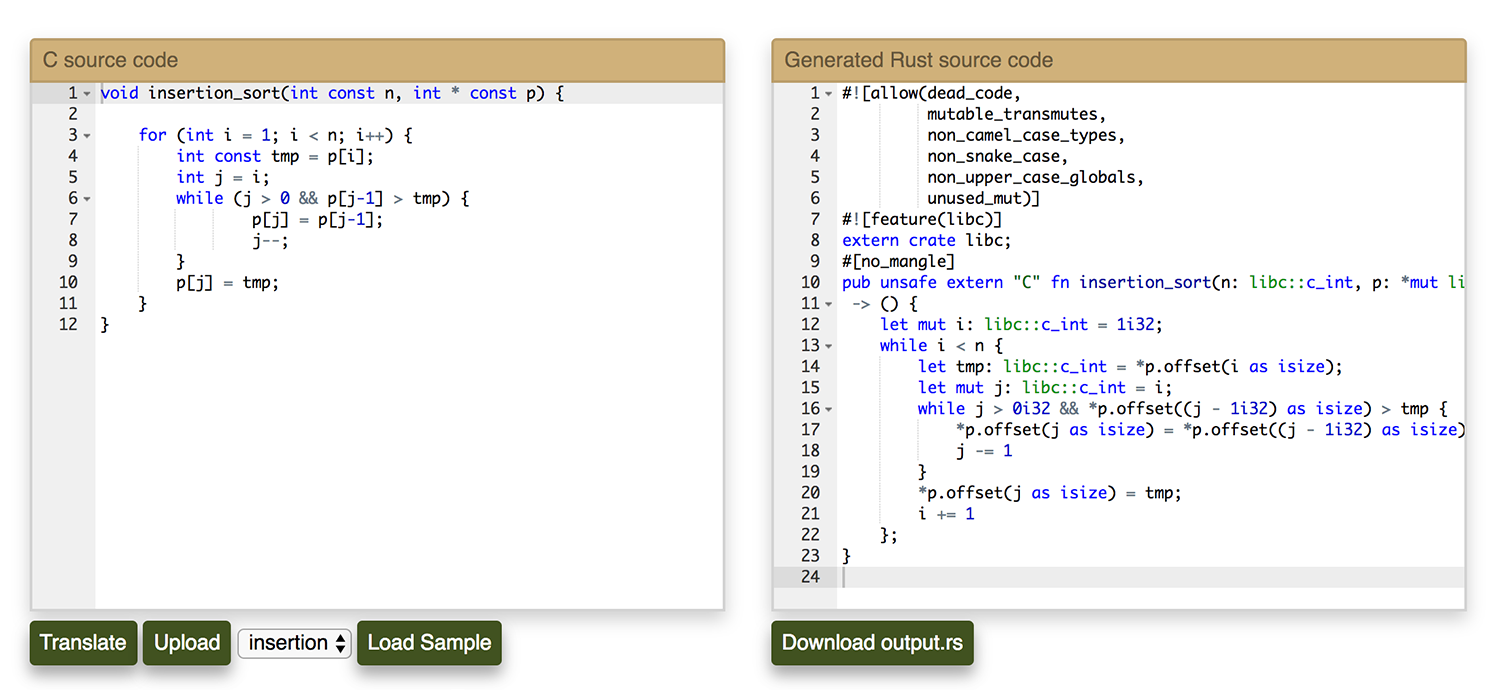
Rust improves on the memory management model of C with a new, checked ownership system. We’d like to be able to migrate C code to take advantage of this. Along the way we’d like to avoid introducing new bugs during translation. To support this we are developing this mechanical translator to handle the initial, error-prone work of the initial port to a new language. C has many opportunities to make a mistake during porting. The control flow structures are slightly different, and C has a lot of implicit cast behavior that can be important to preserve. Once we’ve made that translation to explicit behavior in Rust we can work toward increasingly idiomatic and safe Rust!
Architecture
Understanding C code goes beyond simply translating from one syntax to the other. In order to understand the meaning and behavior of C we have to be able to type-check it. The types will dictate the behaviors of different operators, determine if an operation can overflow or not, and determine implicit coercions. Type checking C is not a trivial process, and it’s not something that we wanted to reimplement. Fortunately there is a high-quality C compiler available that we can use as a library to aid in assisting with the process of understanding C.
Clang
The Clang project offers a C++ library for making clang-based tools called LibTooling. This library solves a couple different problems that are encountered when processing C files: processing command-line flags, running the preprocessor, parsing, and type-checking. It provides access to clang’s lexer, parser, type-checker, various transformation and analysis building blocks, and integrated access to the pre-processor.
We’ve written a tool using LibTooling called ast-extractor that is able to process C files into type-annotated abstract syntax trees (AST). These are suitable for processing by the translator. This AST extractor does no translation itself and simply handles serializing the clang representation of a program into a format suitable for processing by external tools.
In order to make the extracted AST easy to process by multiple tools, we’re using CBOR. This binary format is compact, has a self-describing structure, and has implementations in many languages. Choosing CBOR has saved time in both implementation of the serialization and deserialization process, and it has also helped when we’ve wanted to inspect serialized ASTs directly for debugging purposes.
C files in large projects don’t exist in isolation. They exist in an ecosystem of include paths, preprocessor flags, language extension flags, and more. We can’t ignore all of these flags when processing a C file, and it would be a lot of work to correctly implement the logic to handle all of them. LibTooling has already undertaken the hard work of reaching compatibility with GCC’s flags, and this was no small endeavor. Fortunately we’re able to build on top of this work. Integration with the build systems that provide these flags is a challenge discussed below.
libsyntax
As a Rust compiler, rustc needs to be able to parse and print Rust source code. This functionality is contained in the internal crate libsyntax. This crate makes it possible to reliably parse and print Rust from our own tools and tools like bindgen.
As an internal component of the compiler, this crate is only exposed on nightly releases. Its API is not stable, which means that our use of it requires us to fix to a specific nightly release. Keeping pace with the changes has been a minor inconvenience compared with the benefits of having a complete Rust parser, abstract syntax tree and printer.
Handling comments in an abstract syntax tree is always a challenge. Comments are typically part of the lexical syntax of a language and are removed before parsing happens. Comments are able to fit into places in the syntax where it wouldn’t make sense to have attachment points in the AST. Consider some of the many places one can put comments into a for-loop!
for x /*a*/ in /*b*/ 1 /*c*/ .. /*d*/ 10 { println!("{}",x) }
To handle this, libsyntax tracks comments in parallel to the AST. The comments are then cross-referenced with the AST by byte position. This allows comments to be reinserted into the concrete syntax back to the positions where they were originally parsed from. The byte-oriented placement of comments is a challenge, however, when you’re generating syntax trees programmatically. We don’t know the byte-positions of the final concrete syntax until we actually render our generated AST!
In order to work around needing to know byte-positions, we assign temporary, unique byte-positions to any element that needs a comment attached. As a final pass, we renumber all of these byte-positions to ensure they occur in ascending order in the final AST before we print it. This enables the pretty printer to correctly associate comments with the corresponding concrete syntax.
Challenges
While Rust is able to express most of what C can, there are some areas that require more care when translating. In the following sections a few of the challenges are described.
Build system integration
Software projects are more than a set of source files. We also need to know how to combine all of those source files to produce an executable. Build systems automate the process of compiling source files, specifying extensions, distinguishing search paths, and more. We need this information in able to translate the C files for a project.
LibTooling expects to find the flags used to compile a C source file in a compile commands database file named compile_commands.json. It will automatically use this database when processing C source files. To get all the correct settings in place for clang it’s enough to generate this file.
We have two options for generating the compile commands database automatically. The most direct way is for projects built using CMake which will generate the database when activated with a simple flag. For other projects that aren’t using CMake, we can use Bear. This tool is able to wrap an existing build process and intercept builds commands in order to track the flags that were needed. While the CMake approach is the most convenient, most projects aren’t using CMake to manage their build process. Bear is useful on a wider range of projects, but also involves actually building the projects.
Beyond translating a project we still have the challenge of integrating the generated Rust back into the project’s build process. We don’t have an automated solution for this. Currently it is necessary to invoke the Rust compiler to create a single static library from all of the translated Rust sources and to link that library into the project.
CPP and Macros
In order to be able to write more portable, efficient, and compact code C programs are run through a pre-processor before actually being compiled. This allows a C program to be customized uniquely for each platform that it is run on before being compiled, and it also helps address some of the limited abstraction facilities in the C language.
While both useful and powerful, the C pre-processor (CPP) operates at the level of string concatenation. It neither knows nor respects the syntactic structures of C. This means that it is generally impossible to parse a file using CPP as having anything to do with C. In order to perform our translation we need to be able to parse and type-check the C source code. This forces us to operate on the output of the CPP and means that our translation will lose the abstractions that only exist in CPP code as these abstractions live at the superficial level of string concatenation. On the other hand, this extreme flexibility means that C files can use syntax that will only be valid on some platforms and hide this compatibility code from parsing on others.
LibTooling does provide support for tracking source positions corresponding to both macro location and expanded source location. Perhaps in the future work we’ll be able to recreate some of the simpler CPP abstractions in the translated Rust. In our current implementation, we lose the CPP abstractions, however.
Control Flow
Unlike C, Rust has no support for goto or fall-through in switch statements. This led us to need to do an extensive analysis of the control-flow graph of our C programs to transform them to use syntax that exists in Rust.
Static Initializers
Rust is more particular than C when it comes to initializing static variables. There are multiple reasons for this. One reason is that some functionality that is primitive to C is hidden behind method invocations in Rust. When compiling to an object file the compiler needs to know the exact values that a static variable should be initialized with. It doesn’t generate code to do this. Only specially marked const fn methods are able to be called in Rust in these contexts. Another issue derives from Rust’s attempts to be thread-safe. Only certain types are suitable for being stored in static mutable variables.
Loading string literals into static variables was another challenge. The type of Rust string and byte-string literals does not correspond to those in C. This requires us to perform a chain of casts in some cases to get equivalent behavior, where we would be able to write shorter translations outside of the initializers.
To work around these limitations and others related to pointers into static variable, we lift some static variable initializers out to a top-level initialization function. This function will need to be run when the module is loaded. In other cases we are able to produce messier code that is able to work around the Rust limitations and without extracting the initializers to a top-level function. While this approach works, we anticipate these initializers will be an early target for refactoring.
Variable-length Arrays
Variable-length arrays (VLA) are an useful feature added in C99. These allow for arrays to be dynamically sized while still being declared as automatic variables. Perhaps surprisingly these can also be used in function arguments as seen below.
void example(int a, int b, int c, int my_array[a][b][c]) { ... }
pub unsafe extern "C" fn example
(mut a: c_int, mut b: c_int, mut c: c_int,
mut my_array: *mut libc::c_int) {
let vla_0 = b as usize;
let vla_1 = c as usize;
...
}
To provide C implementation flexibility, the standard places no requirements on where these arrays are actually allocated. This frees our translation to be able to use the standard Rust Vec type. VLAs are never initialized in C code. In our translation we compute and store all of the size components of a VLA and declaration time and then save those components for use later when computing offsets into the array. Caching these values becomes important because the sizes can be computed from arbitrary expressions (including function calls) and the variables that these sizes are computed from can change later (without affecting the array).
Beyond finding a way to allocate VLAs, the translation also needs to be able to compute indices into VLAs. These index computations require dynamically computing the strides for the various index components. These computations will use the cache size values as seen in the example code above (e.g. vla_0).
Perhaps surprisingly, nested VLAs are not represented as nested Rust Vec types but as a single flat Vec with computed offsets. This is due to layout requirements in C. VLAs need to be compatible with their non-VLA counterparts. While we back VLAs with Vec we actually pass them around as pointers (as seen in the example).
Variadic Functions
Typical C code, including the standard C library, makes use of variable argument functions. Unfortunately, Rust has limited support for variable argument functions. Our translator does the best that it can to support the features that fit into Rust.
Rust supports importing variadic C functions. This means that we can translate code that calls functions like printf. When calling these functions it is necessary for the Rust code to manually promote arguments. Fortunately these promotions are already computed by clang for us in the exported AST.
In upcoming work, Rust will support writing functions that manipulate va_list values manually. This means that we can translate functions like vprintf. We currently support the proposed form of this feature, though using it requires a custom-compiled rustc.
We don’t currently have a way to define new variadic functions. This means our translator is unable to process such function definitions during translation. Our current work-around is to declare these as external functions and require them to be compiled as C manually. The programmer performing the translation would need to refactor the code to not need this feature to finish translating to Rust.
Note
This research was developed with funding from the Defense Advanced Research Projects Agency (DARPA). The views, opinions and/or findings expressed are those of the author and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government.